🔥 News!!!
- [2025/04] We release the model checkpoints and inference code. [New!]
🔥 News!!!
In this work, we embrace the RL paradigm and introduce ReTool, a Tool-augmented Reinforcement learning framework explicitly designed to guide LLMs towards optimal strategies for leveraging external computational tools during reasoning. Our comprehensive experiments on AIME2024 and AIME2025 demonstrate that ReTool not only achieves superior accuracy compared to conventional text-based RL approaches, but also converges with significantly fewer training steps.
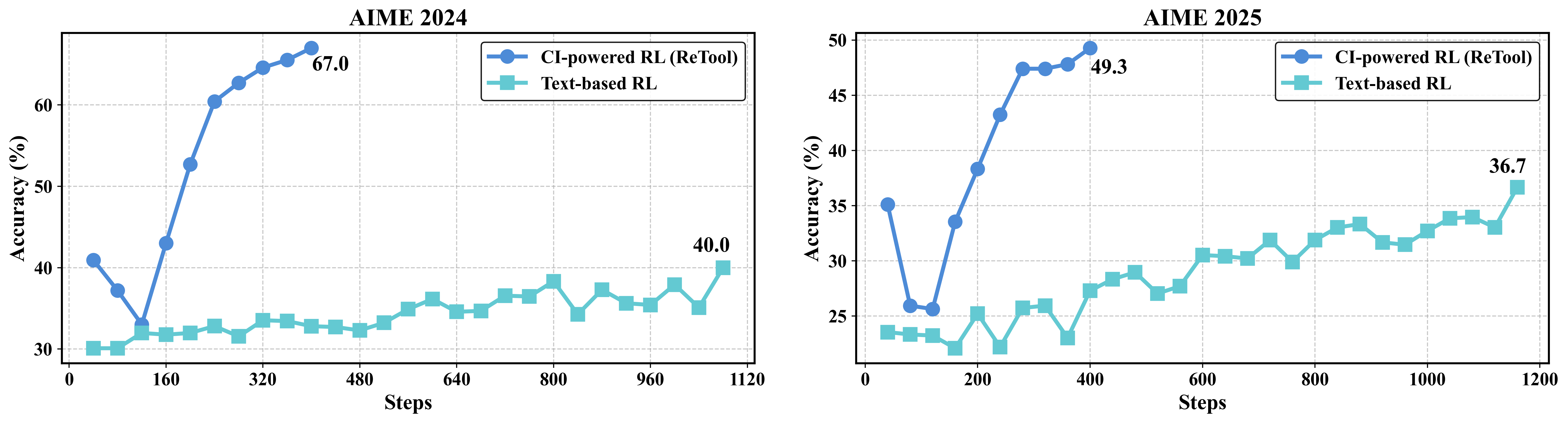
To benefit the broader research community, we will open-source the recipe of ReTool soon, including algorithm details, model weights, dataset and code. We utilize verl to perform RL training.
We provide training and validation datasets for Retool training.
We adopt the same rule-based verifier with DAPO via string normalization and matching.
We provide the model weights of ReTool-Qwen-32B and ReTool-DeepSeek-R1-Distill-Qwen-32B, which are trained based on Qwen2.5-32B-Instruct and DeepSeek-R1-Distill-Qwen-32B. The inference framework can be found in code.
If you find our project helpful, please cite:
@misc{feng2025retoolreinforcementlearningstrategic,
title={ReTool: Reinforcement Learning for Strategic Tool Use in LLMs},
author={Jiazhan Feng and Shijue Huang and Xingwei Qu and Ge Zhang and Yujia Qin and Baoquan Zhong and Chengquan Jiang and Jinxin Chi and Wanjun Zhong},
year={2025},
eprint={2504.11536},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.11536},
}